
User Managed
- The NVIDIA GPU Operator is an operator that simplifies the deployment and management of GPU nodes in Kubernetes clusters. It provides a set of Kubernetes custom resources and controllers that work together to automate the management of GPU resources in a Kubernetes cluster.
- In this guide, we will show you how to:
- Create a nodegroup with NVIDIA GPUs in a VKS cluster.
- Install the NVIDIA GPU Operator in a VKS cluster.
- Deploy your GPU workload in a VKS cluster.
- Configure GPU Sharing in a VKS cluster.
- Monitor GPU resources in a VKS cluster.
- Autoscale GPU resources in a VKS cluster.
Prerequisites
-
A VKS cluster with at least one NVIDIA GPU nodegroup.
-
kubectlcommand-line tool installed on your machine. For more information, see Install and Set Up kubectl. -
helmcommand-line tool installed on your machine. For more information, see Installing Helm. -
(Optional) Other tools and libraries that you can use to monitor and manage your Kubernetes resources:
kubectl-view-allocationsplugin for monitoring cluster resources. For more information, see kubectl-view-allocations.
-
The image below shows my machine setup, it will be used in this guide:
# Check kubectl CLI version kubectl version # Check Helm version helm version # Check kubectl-view-allocations version kubectl-view-allocations --version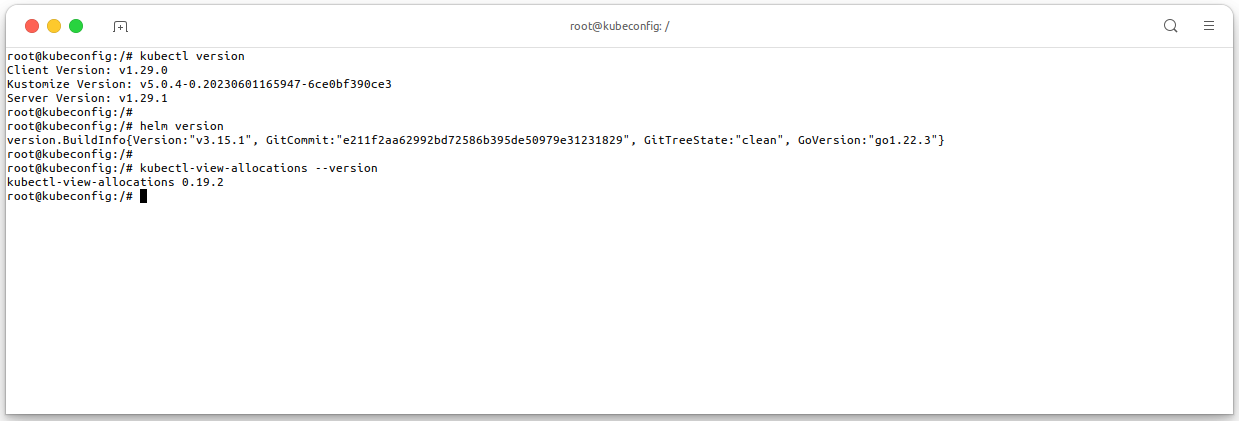
-
And this is my VKS cluster with 1 NVIDIA GPU nodegroup, it will be used in this guide, execute the following command to check the nodegroup in your cluster:
kubectl get nodes -owide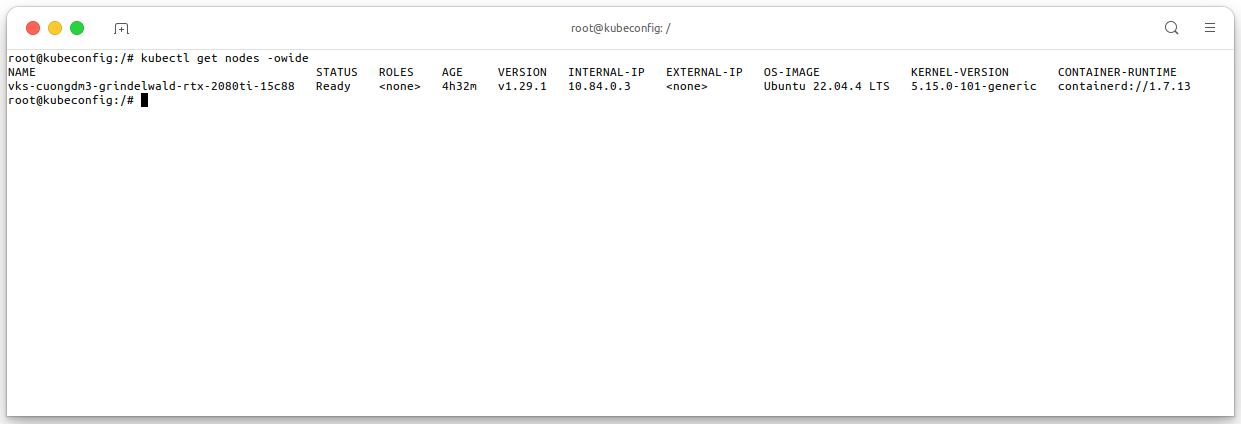
Installing the GPU Operator
-
This guide only focus on installing the NVIDIA GPU Operator, for more information about the NVIDIA GPU Operator, see NVIDIA GPU Operator Documentation. We manually install the NVIDIA GPU Operator in a VKS cluster by using Helm charts, execute the following command to install the NVIDIA GPU Operator in your VKS cluster:
helm install nvidia-gpu-operator --wait --version v24.3.0 \ -n gpu-operator --create-namespace \ oci://vcr.vngcloud.vn/81-vks-public/vks-helm-charts/gpu-operator \ --set dcgmExporter.serviceMonitor.enabled=true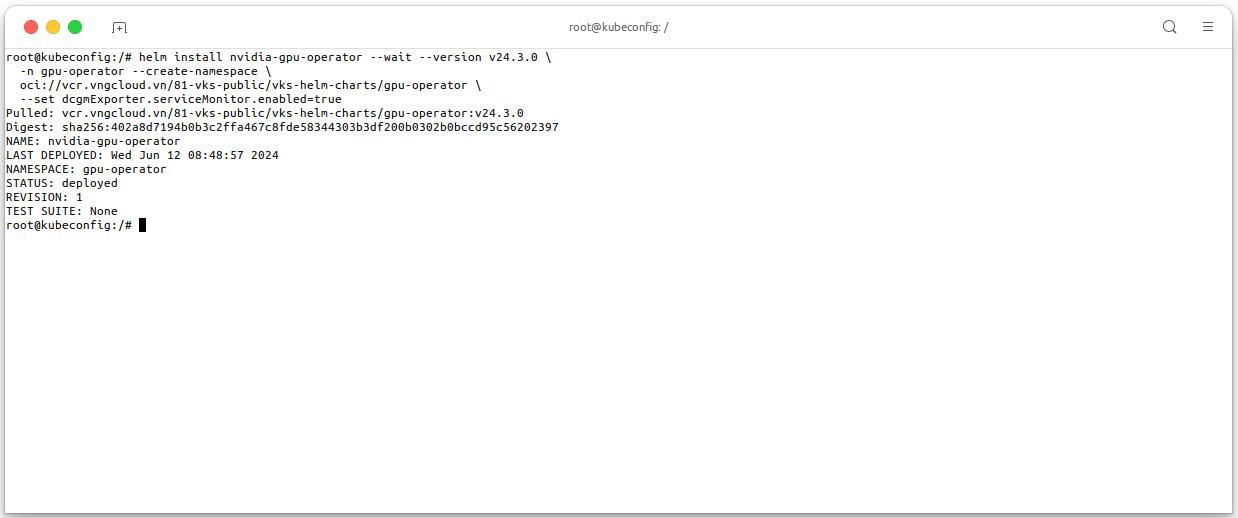
-
You MUST wait for the installation to complete (about 5-10 minutes), execute the following command to check all the pods in the
gpu-operatornamespace are running:kubectl -n gpu-operator get pods -owide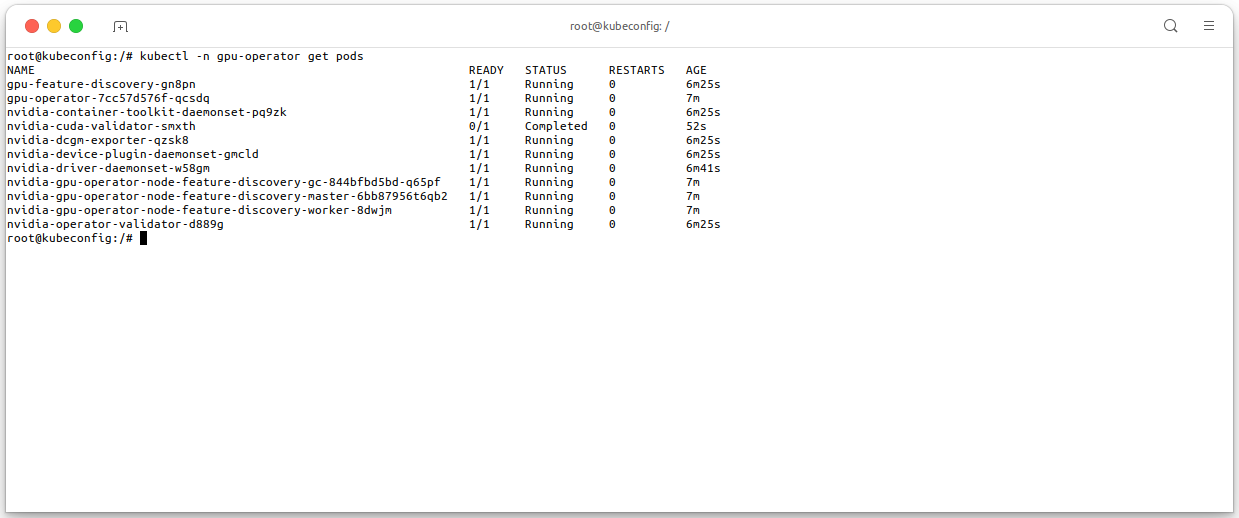
-
The operator will label the node with the
nvidia.com/gpulabel, which can be used to filter the nodes that have GPUs. Thenvidia.com/gpulabel is used by the NVIDIA GPU Operator to identify nodes that have GPUs. The NVIDIA GPU Operator will only deploy the NVIDIA GPU device plugin on nodes that have thenvidia.com/gpulabel.kubectl get node -o json | jq '.items[].metadata.labels' | grep "nvidia.com"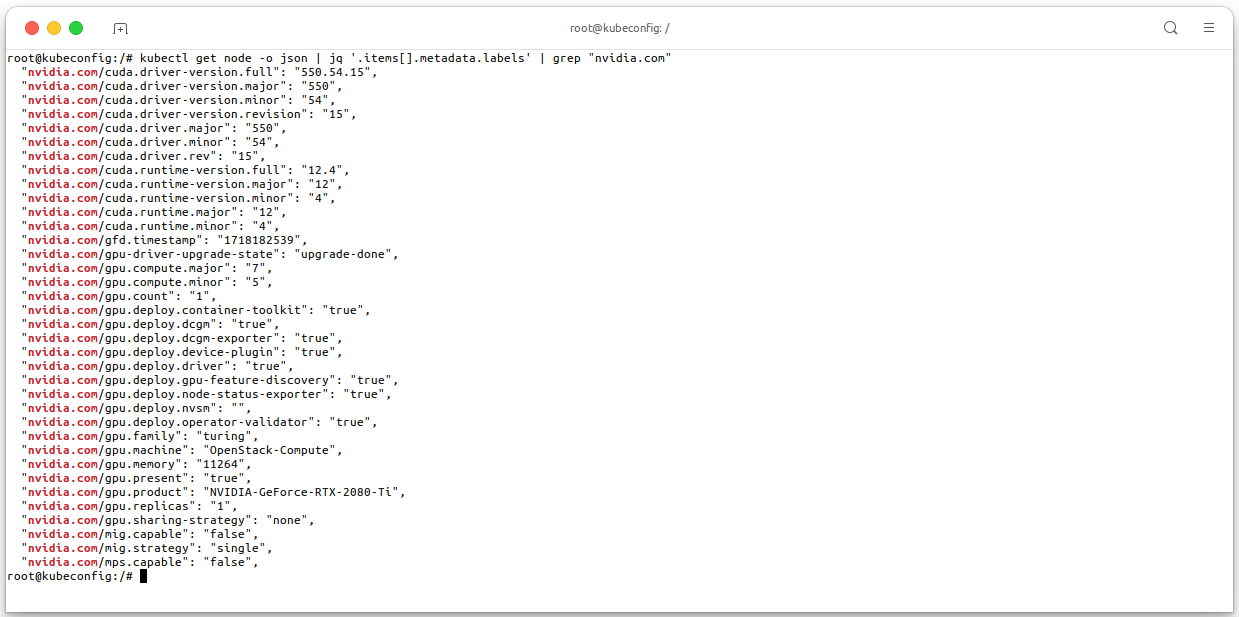
- For the above result, the single node in the cluster has the
nvidia.com/gpulabel, which means that the node has GPUs. - These labels also tell that this node is using 1 card of RTX 2080Ti GPU, number of available GPUs, the GPU Memory and other information.
- For the above result, the single node in the cluster has the
-
On the pod
nvidia-device-plugin-daemonsetin thegpu-operatornamespace, you can executenvidia-smicommand to check the GPU information of the node:POD_NAME=$(kubectl -n gpu-operator get pods -l app=nvidia-device-plugin-daemonset -o jsonpath='{.items[0].metadata.name}') kubectl -n gpu-operator exec -it $POD_NAME -- nvidia-smi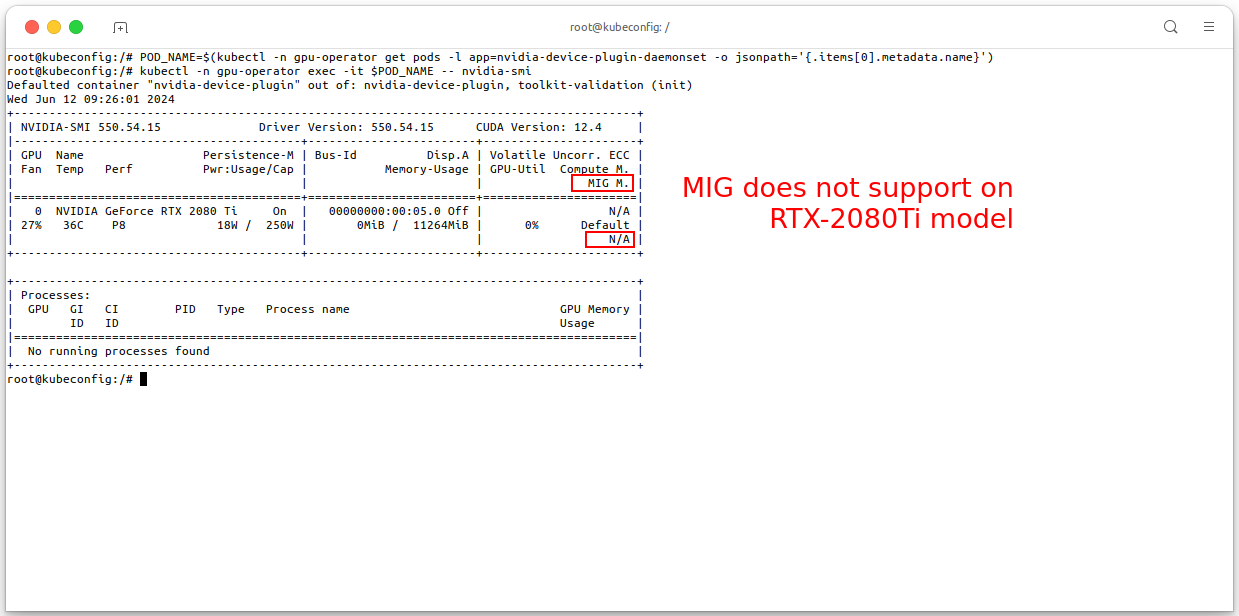
Deploy your GPU workload
Cuda VectorAdd Test
-
In this section, we will show you how to deploy a GPU workload in a VKS cluster. We will use the
cuda-vectoradd-testworkload as an example. Thecuda-vectoradd-testworkload is a simple CUDA program that adds two vectors together. The program is provided as a container image that you can deploy in your VKS cluster. See file cuda-vectoradd-test.yaml.# Apply the manifest kubectl apply -f \ https://raw.githubusercontent.com/vngcloud/kubernetes-sample-apps/main/nvidia-gpu/manifest/cuda-vectoradd-test.yaml # Check the pods kubectl get pods # Check the logs of the pod kubectl logs cuda-vectoradd # [Optional] Clean the resources kubectl delete deploy cuda-vectoradd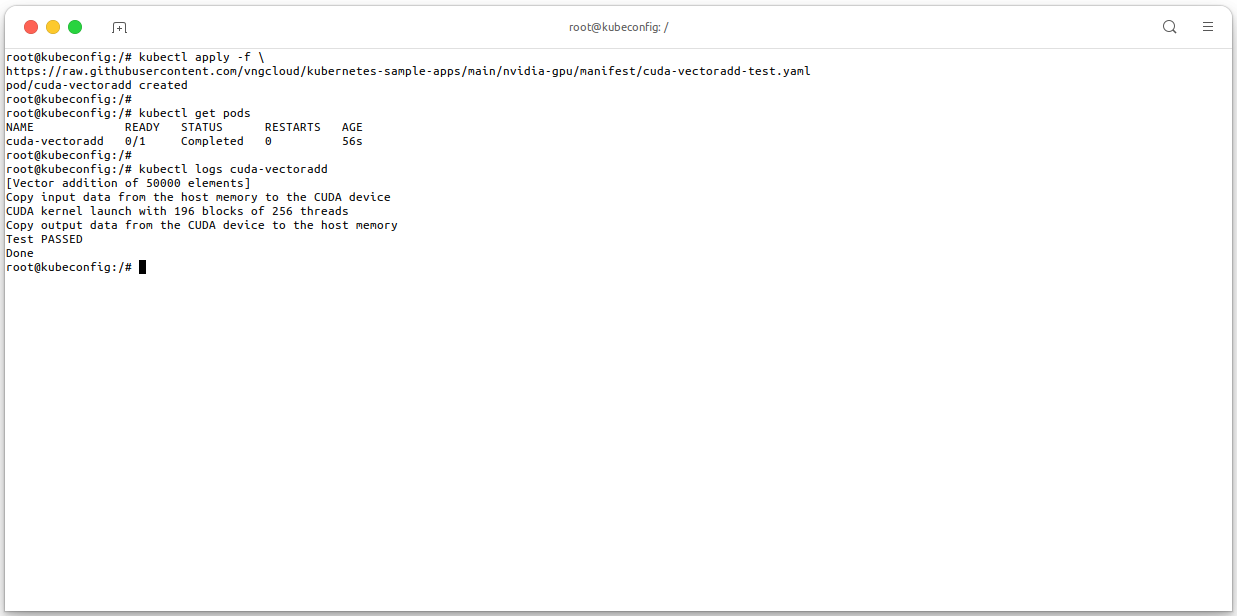
TensorFlow Test
-
In this section, we apply a
Deploymentmanifest for a TensorFlow GPU application. The purpose of thisDeploymentis to create and manage a single pod running a TensorFlow container that utilizes GPU resource for executing the sum of random values from a normal distribution of size \( 100000 \) by \( 100000 \). For more detail about the manifest, see file tensorflow-gpu.yaml# Apply the manifest kubectl apply -f \ https://raw.githubusercontent.com/vngcloud/kubernetes-sample-apps/main/nvidia-gpu/manifest/tensorflow-gpu.yaml # Check the pods kubectl get pods # Check processes are running using nvidia-smi kubectl -n gpu-operator exec -it <put-your-nvidia-driver-daemonset-pod-name> -- nvidia-smi # Check the logs of the TensorFlow pod kubectl logs <put-your-tensorflow-gpu-pod-name> --tail 20 # [Optional] Clean the resources kubectl delete deploy tensorflow-gpu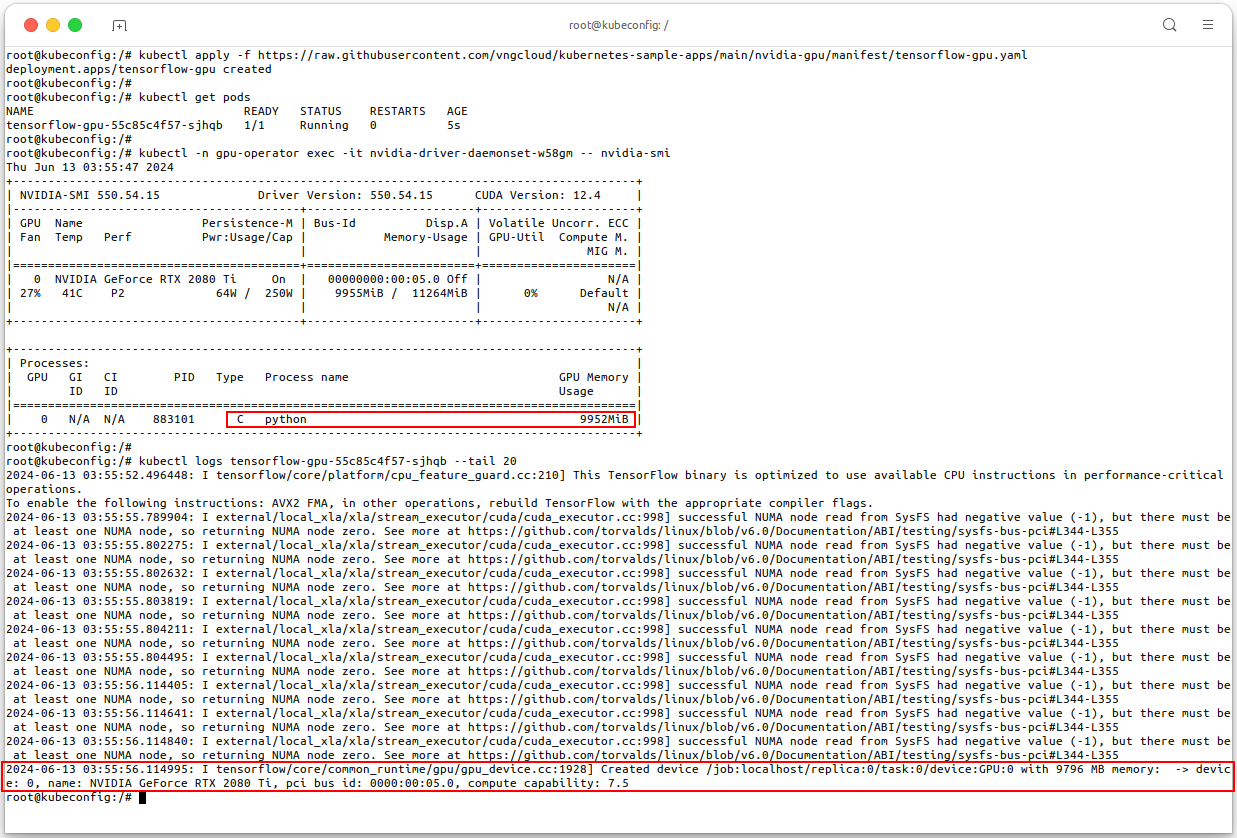
Configure GPU Sharing
-
GPU sharing strategies allow multiple containers to efficiently use your attached GPUs and save running costs. The following tables summarizes the difference between the GPU sharing modes supported by NVIDIA GPUs:
Sharing mode Supported by VKS Workload isolation level Pros Cons Suitable for these workloads Multi-instance GPU (MIG) ❌ Best - Processes are executed in parallel
- Full isolation (dedicated memory and compute resources)
- Supported by fewer GPU models (only Ampere or more recent architectures)
- Coarse-grained control over memory and compute resources
- Recommended for workloads running in parallel and that need certain resiliency and QoS. For example, when running AI inference workloads, multi-instance GPU multi-instance GPU allows multiple inference queries to run simultaneously for quick responses, without slowing each other down.
GPU Time-slicing ✅ None - Processes are executed concurrently
- Supported by older GPU architectures (Pascal or newer)
- No resource limits
- No memory isolation
- Lower performance due to context-switching overhead
- Recommended for bursty and interactive workloads that have idle periods. These workloads are not cost-effective with a fully dedicated GPU. By using time-sharing, workloads get quick access to the GPU when they are in active phases.
- GPU time-sharing is optimal for scenarios to avoid idling costly GPUs where full isolation and continuous GPU access might not be necessary, for example, when multiple users test or prototype workloads.
- Workloads that use time-sharing need to tolerate certain performance and latency compromises.
Multi-process server (MPS) ✅ Medium - Processes are executed parallel
- Fine-grained control over memory and compute resources allocation
- No error isolation and memory protection
- Recommended for batch processing for small jobs because MPS maximizes the throughput and concurrent use of a GPU. MPS allows batch jobs to efficiently process in parallel for small to medium sized workloads.
- NVIDIA MPS is optimal for cooperative processes acting as a single application. For example, MPI jobs with inter-MPI rank parallelism. With these jobs, each small CUDA process (typically MPI ranks) can run concurrently on the GPU to fully saturate the whole GPU.
- Workloads that use CUDA MPS need to tolerate the memory protection and error containment limitations.
GPU time-slicing
- VKS uses the built-in timesharing ability provided by the NVIDIA GPU and the software stack. Starting with the Pascal architecture, NVIDIA GPUs support instruction level preemption. When doing context switching between processes running on a GPU, instruction-level preemption ensures every process gets a fair timeslice. GPU time-sharing provides software-level isolation between the workloads in terms of address space isolation, performance isolation, and error isolation.
Configure GPU time-slicing
-
To enable GPU time-slicing, you need to configure a
ConfigMapwith the following settings:apiVersion: v1 kind: ConfigMap metadata: name: gpu-sharing-config data: any: |- version: v1 flags: migStrategy: none # Disable MIG, MUST be none in the case your GPU is not supported MIG sharing: timeSlicing: resources: - name: nvidia.com/gpu # Only apply for the node with the node.status contains 'nvidia.com/gpu' replicas: 4 # Allow 4 pods to share the GPU, SHOULD less than 48 pods -
The above manifest allows 4 pods to share the GPU. The
replicasfield specifies the number of pods that can share the GPU. Thereplicasfield should be less than the number of GPUs on the node. Thenvidia.com/gpulabel is used to filter the nodes that have GPUs. ThemigStrategyfield is set tononeto disable MIG. -
This configuration will apply to all nodes in the cluster that have the
nvidia.com/gpulabel. To apply the configuration, execute the following command:kubectl -n gpu-operator create -f \ https://raw.githubusercontent.com/vngcloud/kubernetes-sample-apps/main/nvidia-gpu/manifest/time-slicing-config-all.yaml -
And then you need to patch the
ClusterPolicyto enable GPU time-slicing using theanysetting:# Patch the ClusterPolicy kubectl patch clusterpolicies.nvidia.com/cluster-policy \ -n gpu-operator --type merge \ -p '{"spec": {"devicePlugin": {"config": {"name": "gpu-sharing-config", "default": "any"}}}}' # Disable DCGM exporter, time-slicing not support DCGM exporter kubectl patch clusterpolicies.nvidia.com/cluster-policy \ -n gpu-operator --type merge \ -p '{"spec": {"dcgmExporter": {"enabled": false}}}'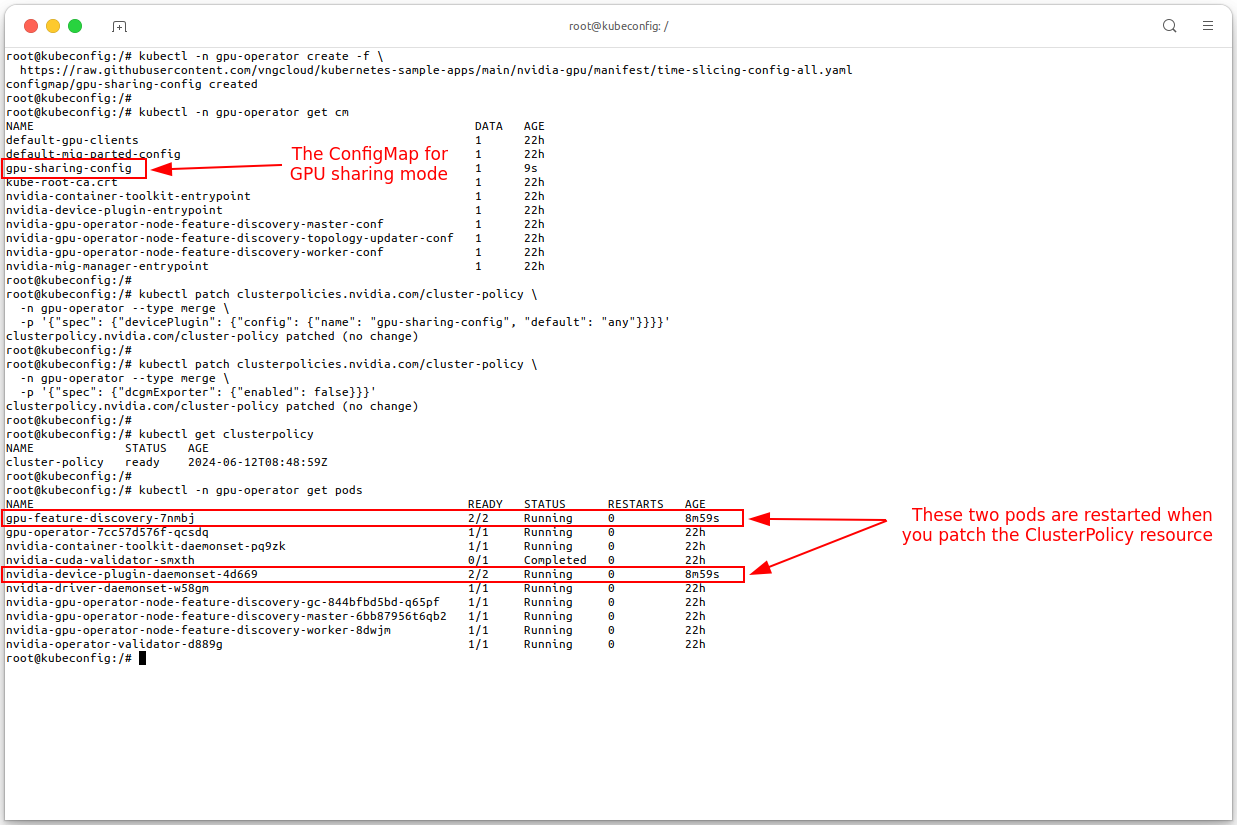
- Your new configuration will be applied to all nodes in the cluster that have the
nvidia.com/gpulabel. - The configuration is considered successful if the
ClusterPolicySTATUS isready. - Because of the
sharing.timeSlicing.resources.replicasis set to 4, you can deploy up to 4 pods that share the GPU. - My cluster has only 1 GPU node, so I can deploy up to 4 pods that share the GPU.
- Your new configuration will be applied to all nodes in the cluster that have the
Verify GPU time-slicing
-
Until now, we have configured the GPU time-slicing, now we will deploy 5 pods that share the GPU using
Deployment, because of only 4 pods can share the GPU, the 5th pod will be inPendingstate. See file time-slicing-verification.yaml.# Apply the manifest kubectl apply -f \ https://raw.githubusercontent.com/vngcloud/kubernetes-sample-apps/main/nvidia-gpu/manifest/time-slicing-verification.yaml # Check the pods kubectl get pods # Check the logs of the TensorFlow pod kubectl logs <put-your-time-slicing-verification-pod-name> --tail 10 # Get the event of pending pod kubectl events | grep "FailedScheduling" # [Optional] Clean the resources kubectl delete deploy time-slicing-verification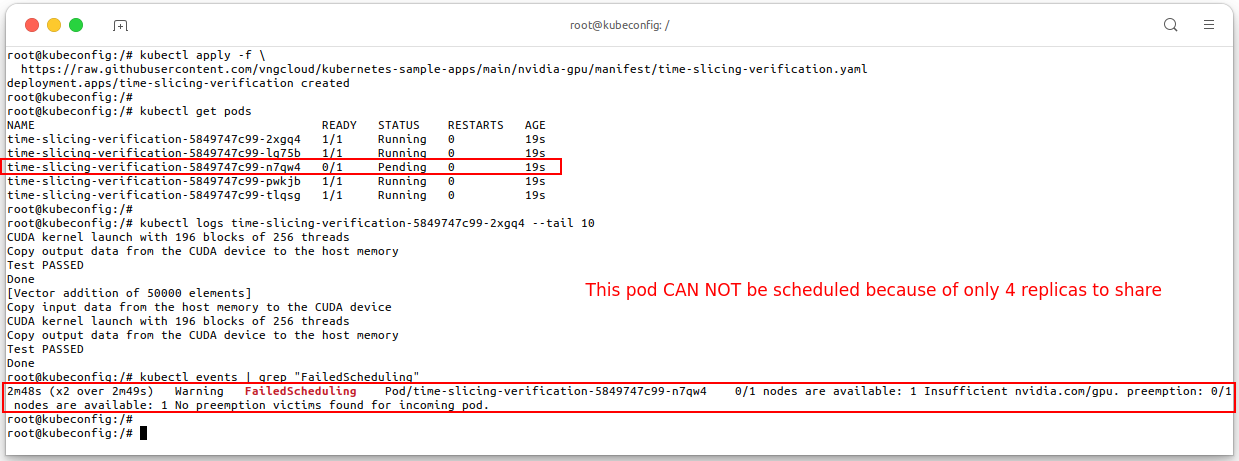
Multi-process server (MPS)
- VKS uses NVIDIA's Multi-Process Service (MPS). NVIDIA MPS is an alternative, binary-compatible implementation of the CUDA API designed to transparently enable co-operative multi-process CUDA workloads to run concurrently on a single GPU device. GPU with NVIDIA MPS provides software-level isolation in terms of resource limits (active thread percentage and pinned device memory).
Configure MPS
-
To enable GPU MPS, you need to update the previous
ConfigMapwith the following settings:apiVersion: v1 kind: ConfigMap metadata: name: gpu-sharing-config data: any-mps: |- version: v1 flags: migStrategy: none # MIG strategy is not used, this field SHOULD depends on your GPU model sharing: mps: # Enable MPS for the GPU resources: - name: nvidia.com/gpu # Only apply for the node with the node.status contains 'nvidia.com/gpu' replicas: 4 # Allow 4 pods to share the GPU -
Now let's apply this new
ConfigMapand then patching theClusterPolicylike the way at the GPU time-slicing section.# Delete the old configmap kubectl -n gpu-operator delete cm gpu-sharing-config kubectl -n gpu-operator create -f \ https://raw.githubusercontent.com/vngcloud/kubernetes-sample-apps/main/nvidia-gpu/manifest/mps-config-all.yaml # Patch the ClusterPolicy kubectl patch clusterpolicies.nvidia.com/cluster-policy \ -n gpu-operator --type merge \ -p '{"spec": {"devicePlugin": {"config": {"name": "gpu-sharing-config", "default": "any-mps"}}}}' # Disable DCGM exporter, MPS not support DCGM exporter kubectl patch clusterpolicies.nvidia.com/cluster-policy \ -n gpu-operator --type merge \ -p '{"spec": {"dcgmExporter": {"enabled": false}}}' # Check MPS server is running or not kubectl -n gpu-operator get pods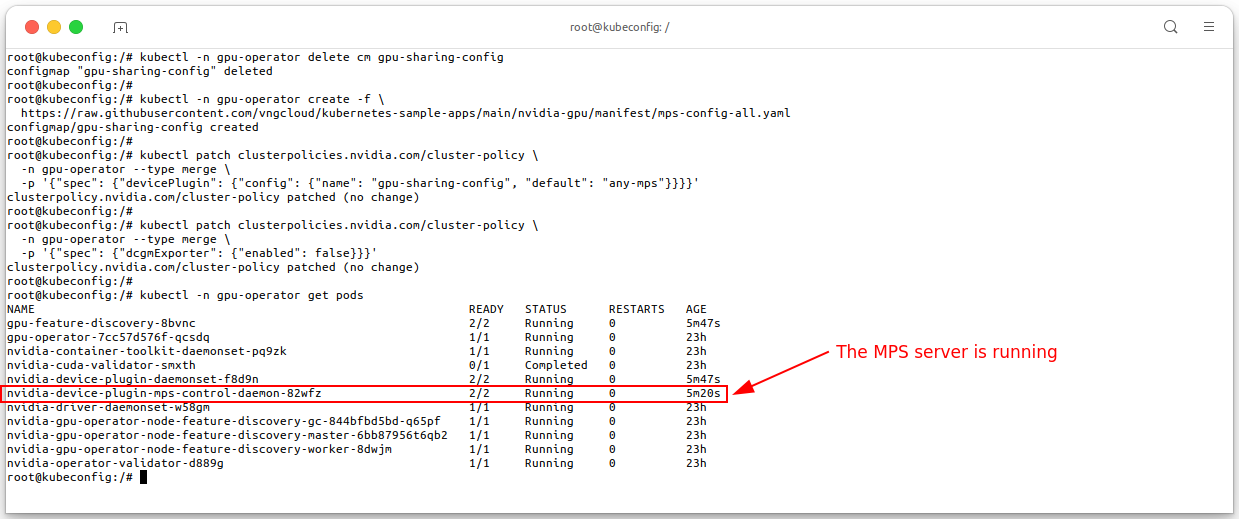
- Your new configuration will be applied to all nodes in the cluster that have the
nvidia.com/gpulabel. - The configuration is considered successful if the
ClusterPolicySTATUS isready. - Because of the
sharing.mps.resources.replicasis set to 4, you can deploy up to 4 pods that share the GPU.
- Your new configuration will be applied to all nodes in the cluster that have the
Verify MPS
-
Until now, we have configured the GPU MPS, now we will deploy 5 pods that share the GPU using
Deployment, because of only 4 pods can share the GPU, the 5th pod will be inPendingstate. See file mps-verification.yaml.# Apply the manifest kubectl apply -f \ https://raw.githubusercontent.com/vngcloud/kubernetes-sample-apps/main/nvidia-gpu/manifest/mps-verification.yaml # Check the pods kubectl get pods # Check the logs of the TensorFlow pod kubectl logs -l job-name=nbody-sample # [Optional] Clean the resources kubectl delete job nbody-sample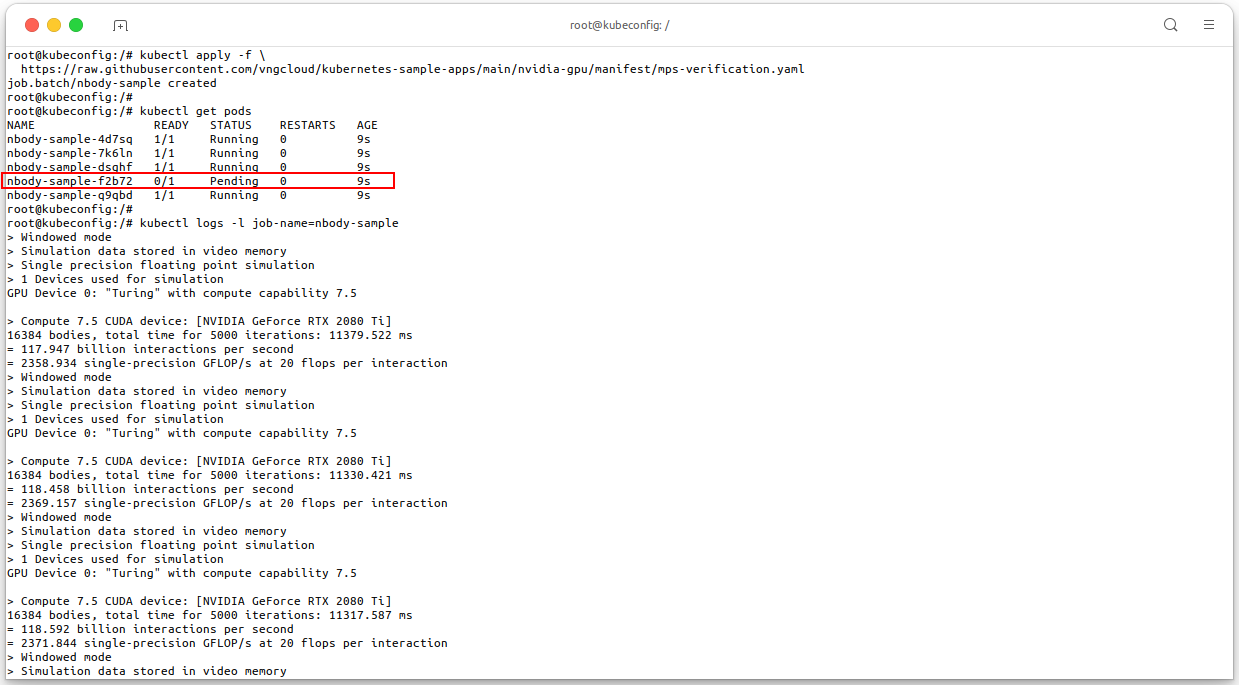
Applying Multiple Node-Specific Configurations
- An alternative to applying one cluster-wide configuration is to specify multiple time-slicing configurations in the
ConfigMapand to apply labels node-by-node to control which configuration is applied to which nodes. - In this guideline, I add a new RTX-4090 into the cluster.
- This configuration should be greate if your cluster have multiple nodes with different GPU models. For example:
- NodeGroup 1 includes the instance of GPU RTX 2080Ti.
- NodeGroup 2 includes the instance of GPU RTX 4090.
- And if you want to run multiple GPU sharing strategies in the same cluster, you can apply multiple configurations to the same node by using labels. For example:
- NodeGroup 1 includes the instance of GPU RTX 2080Ti with 4 pods sharing the GPU using time-slicing.
- NodeGroup 2 includes the instance of GPU RTX 4090 with 8 pods sharing the GPU using MPS.
Configure Multiple Node-Specific Configurations
-
To using this feature, you need to update the previous
ConfigMapwith the following settings:apiVersion: v1 kind: ConfigMap metadata: name: gpu-multi-sharing-config data: rtx-2080ti: |- # Same the name with the name that you label the GPU node before version: v1 flags: migStrategy: none # MIG strategy is not used, this field SHOULD depends on your GPU model sharing: timeSlicing: resources: - name: nvidia.com/gpu replicas: 4 # Allow the node using this GPU to be shared by 4 pods rtx-4090: |- # Same the name with the name that you label the GPU node before version: v1 flags: migStrategy: none # MIG strategy is not used, this field SHOULD depends on your GPU model sharing: mps: resources: - name: nvidia.com/gpu replicas: 8 # Allow the node using this GPU to be shared by 8 pods -
Apply the above configure.
kubectl -n gpu-operator create -f \ https://raw.githubusercontent.com/vngcloud/kubernetes-sample-apps/main/nvidia-gpu/manifest/multiple-gpu-sharing.yaml # Patch the ClusterPolicy kubectl patch clusterpolicies.nvidia.com/cluster-policy \ -n gpu-operator --type merge \ -p '{"spec": {"devicePlugin": {"config": {"name": "gpu-multi-sharing-config"}}}}' # Disable DCGM exporter kubectl patch clusterpolicies.nvidia.com/cluster-policy \ -n gpu-operator --type merge \ -p '{"spec": {"dcgmExporter": {"enabled": false}}}' # Check the ClusterPolicy kubectl get clusterpolicy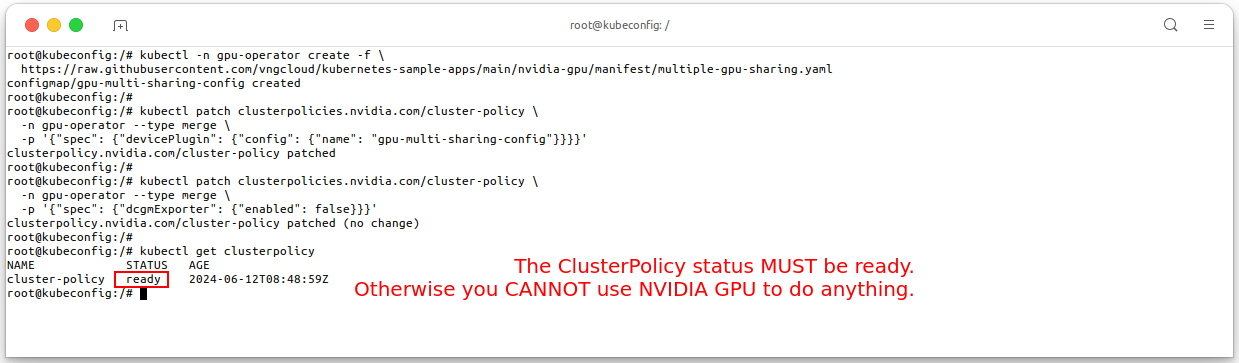
-
Now, we need to label the node with the name that you specified in the
ConfigMap:# Get the node names kubectl get nodes # Label the node with the name that you specified in the ConfigMap kubectl label node <node-name> nvidia.com/device-plugin.config=rtx-2080ti kubectl label node <node-name> nvidia.com/device-plugin.config=rtx-4090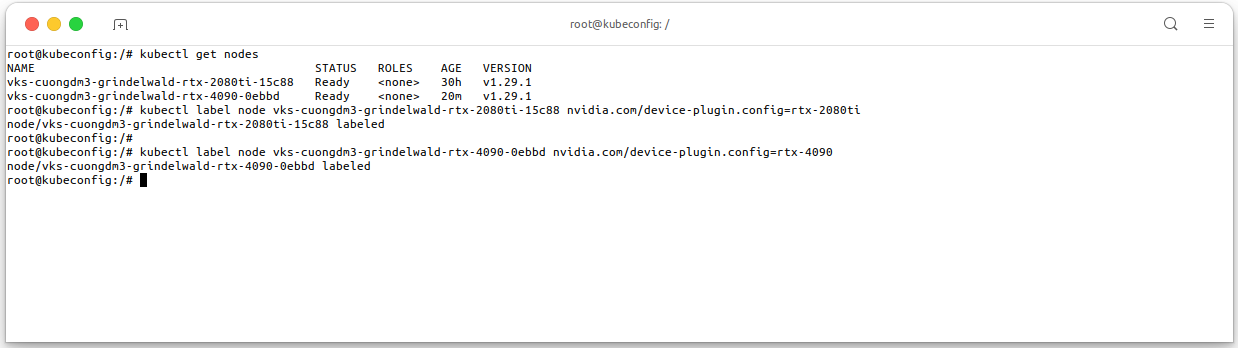
Verify Multiple Node-Specific Configurations
-
In this example, we will training MNIST model in TensorFlow using the GPU RTX 2080Ti and RTX 4090. The RTX 2080Ti will be shared by 4 pods using time-slicing and the RTX 4090 will be shared by 8 pods using MPS. See file tensorflow-mnist-sample.yaml.
# Apply the manifest kubectl apply -f \ https://github.com/vngcloud/kubernetes-sample-apps/raw/main/nvidia-gpu/manifest/tensorflow-mnist-sample.yaml # Check the pods kubectl get pods -owide # Check the logs of the TensorFlow pod kubectl logs <put-your-favourite-tensorflow-mnist-pod-name> --tail 20 # [Optional] Clean the resources kubectl delete deploy tensorflow-mnist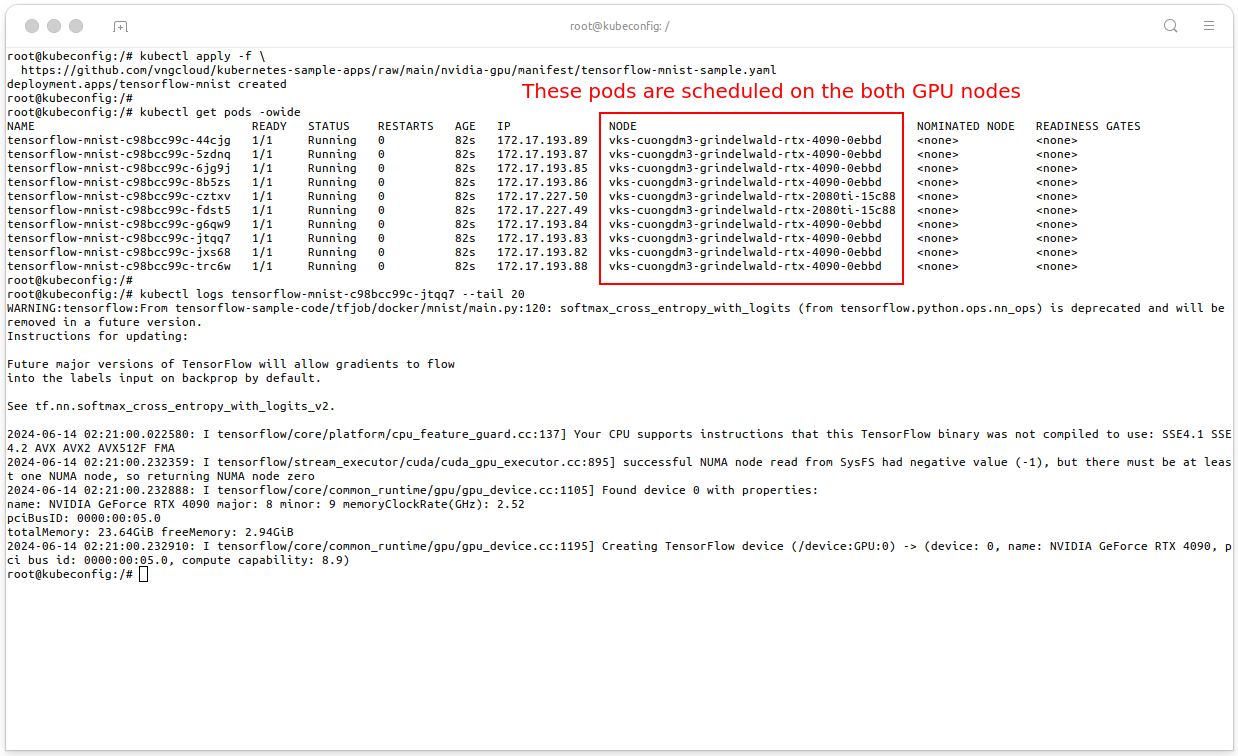
- The pods are running on the node with the GPU RTX 2080Ti and RTX 4090 within different GPU sharing strategies.
Monitoring GPU Resources
-
Monitoring NVIDIA GPU resources in a Kubernetes cluster is essential for ensuring optimal performance, efficient resource utilization, and proactive issue resolution. This overview provides a comprehensive guide to setting up and leveraging Prometheus and the NVIDIA Data Center GPU Manager (DCGM) to monitor GPU resources in a Kubernetes environment.
-
Firstly, we need to install Prometheus Stack and Prometheus Adapter to integrate with the Kubernetes API server. Execute the following command to install the Prometheus Stack and Prometheus Adapter in your VKS cluster:
# Install Prometheus Stack using Helm helm install --wait prometheus-stack \ --namespace prometheus --create-namespace \ oci://vcr.vngcloud.vn/81-vks-public/vks-helm-charts/kube-prometheus-stack \ --version 60.0.2 \ --set prometheus.prometheusSpec.serviceMonitorSelectorNilUsesHelmValues=false # Install and configure Prometheus Adapter using Helm prometheus_service=$(kubectl get svc -n prometheus -lapp=kube-prometheus-stack-prometheus -ojsonpath='{range .items[*]}{.metadata.name}{"\n"}{end}') helm install --wait prometheus-adapter \ --namespace prometheus --create-namespace \ oci://vcr.vngcloud.vn/81-vks-public/vks-helm-charts/prometheus-adapter \ --version 4.10.0 \ --set prometheus.url=http://${prometheus_service}.prometheus.svc.cluster.local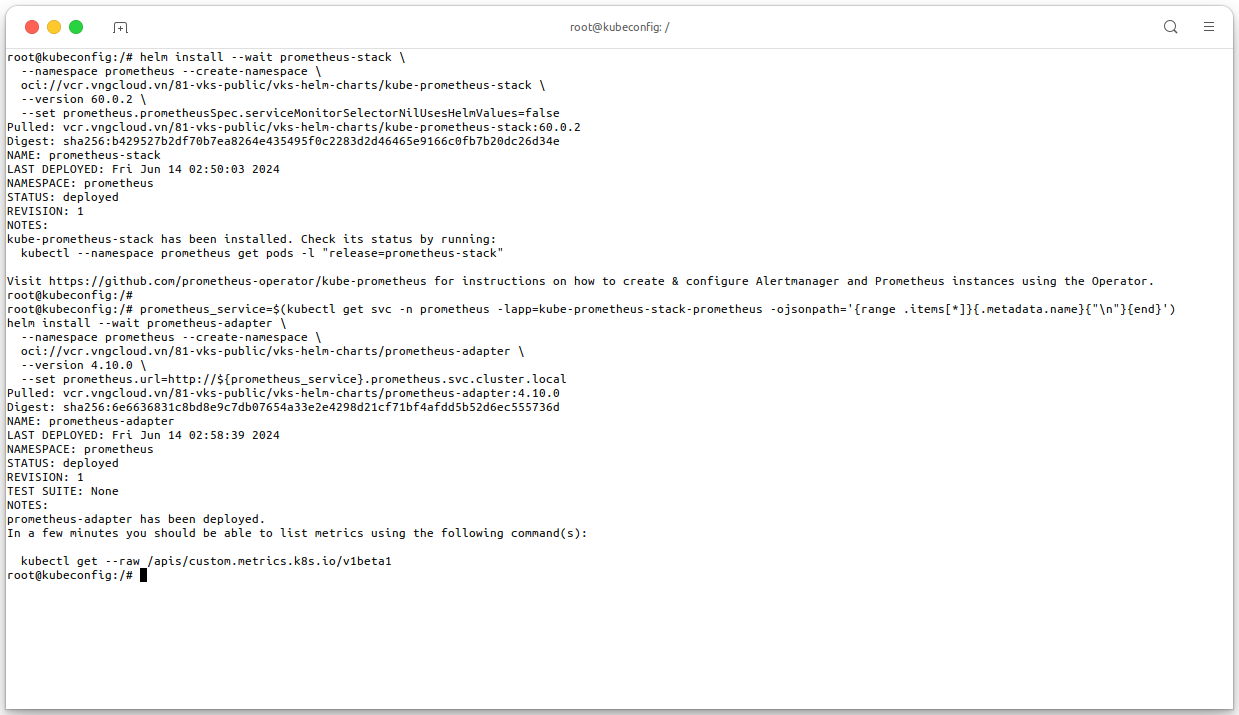
-
After the installation is complete, execute the following command to check the resources of Prometheus are running:
# Check the resources of Prometheus are running kubectl -n prometheus get all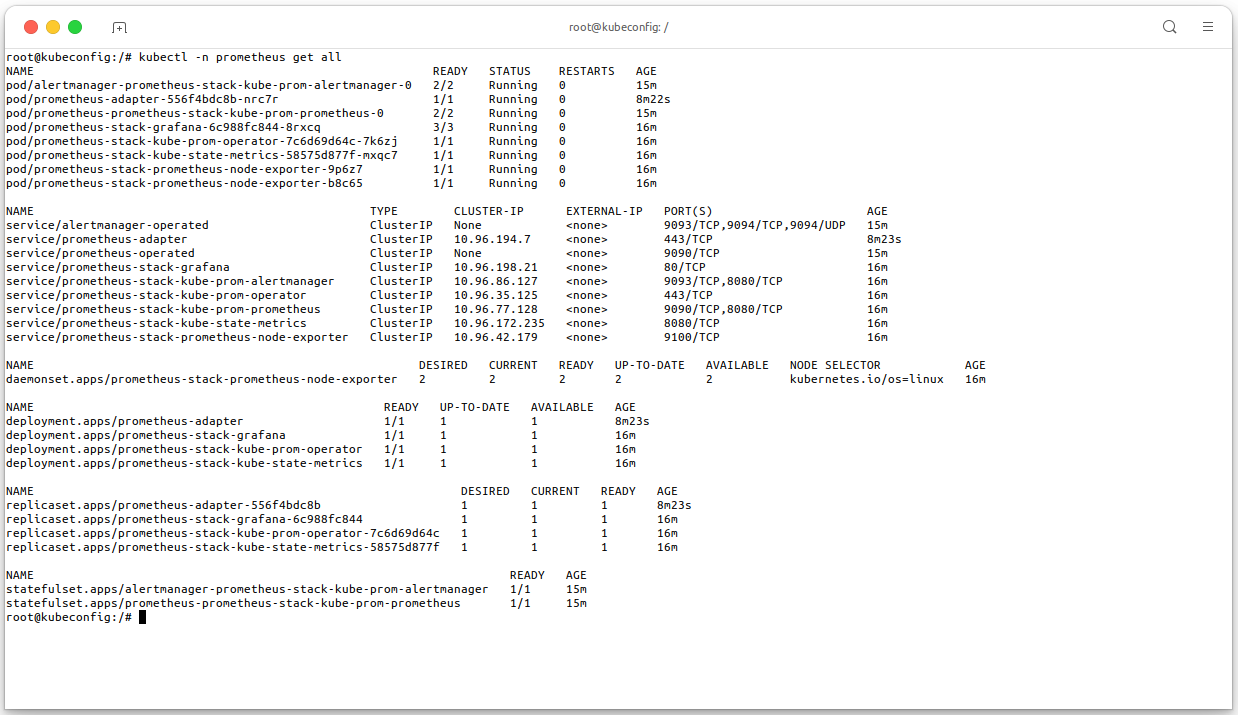
-
Now, we need to enable the DCGM exporter to monitor the GPU resources in the VKS cluster. Execute the following command to enable the DCGM exporter in your VKS cluster:
# Enable the DCGM exporter kubectl patch clusterpolicies.nvidia.com/cluster-policy \ -n gpu-operator --type merge \ -p '{"spec": {"dcgmExporter": {"enabled": true}}}' # Confirm Prometheus can scrape the DCGM exporter metrics, sometime you MUST wait for a few minutes # (about 1-3 mins) for the DCGM exporter to be ready kubectl get --raw /apis/custom.metrics.k8s.io/v1beta1 | jq -r . | grep DCGM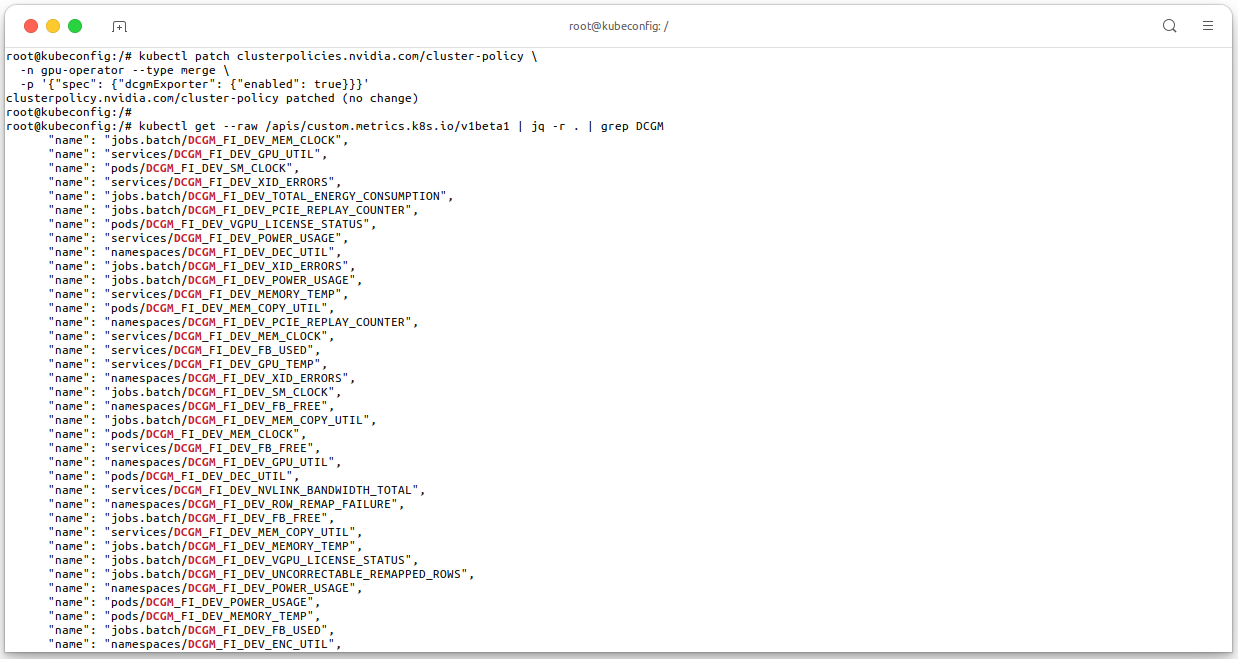
-
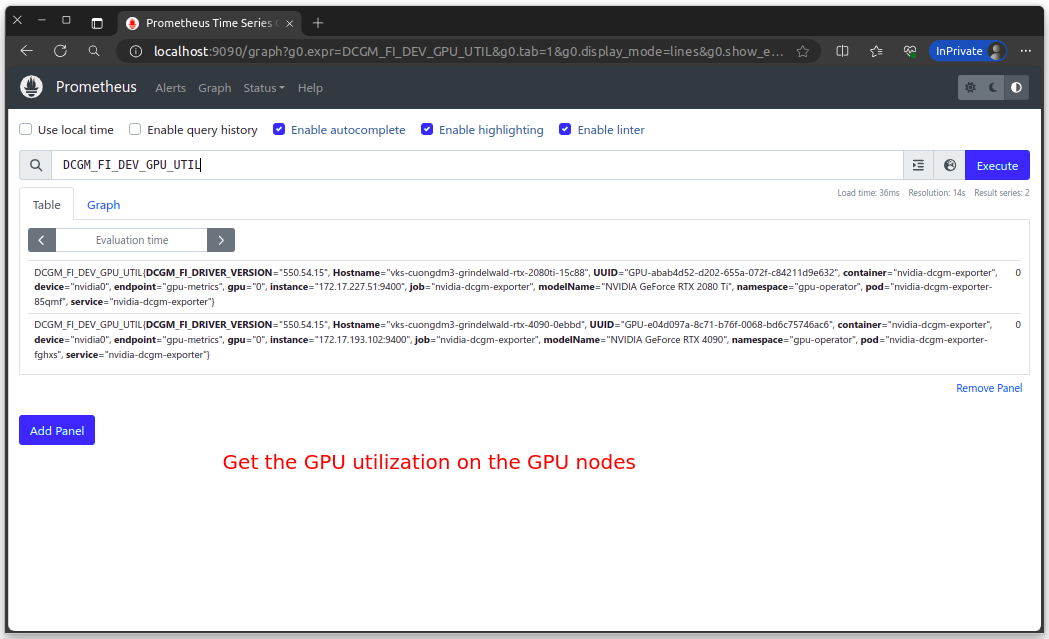
Let's forward the Prometheus Adapter to your local machine to check the GPU metrics by visit http://localhost:9090:
# Forward the Prometheus Adapter to your local machine kubectl -n prometheus \ port-forward svc/prometheus-stack-kube-prom-prometheus 9090:9090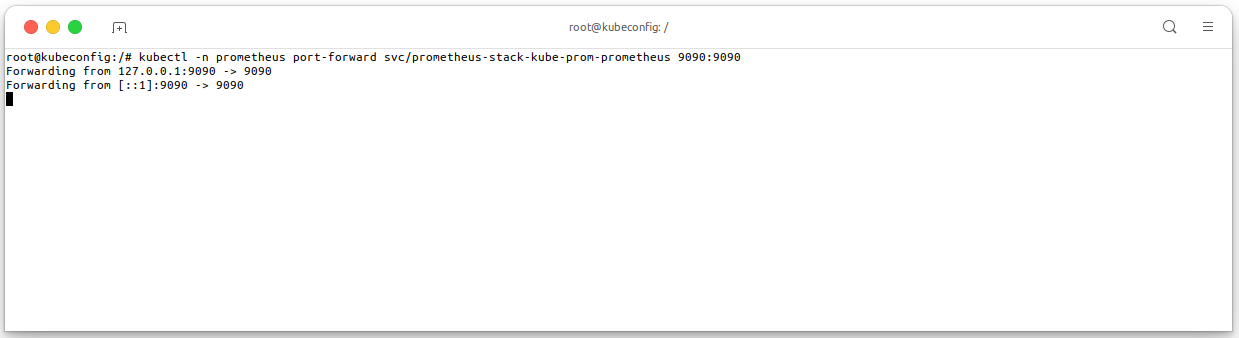
-
The following table lists some observable GPU metrics. For details about more metrics, see Field Identifiers.
-
Table 1: Usage
Metric Name Metric Type Unit Description DCGM_FI_DEV_GPU_UTILGauge Percentage GPU usage. DCGM_FI_DEV_MEM_COPY_UTILGauge Percentage Memory usage. DCGM_FI_DEV_ENC_UTILGauge Percentage Encoder usage. DCGM_FI_DEV_DEC_UTILGauge Percentage Decoder usage. -
Table 2: Memory
Metric Name Metric Type Unit Description DCGM_FI_DEV_FB_FREEGauge MB Number of remaining frame buffers. The frame buffer is called VRAM. DCGM_FI_DEV_FB_USEDGauge MB Number of used frame buffers. The value is the same as the value of memory-usage in the nvidia-smi command. -
Table 3: Temperature and power
Metric Name Metric Type Unit Description DCGM_FI_DEV_GPU_TEMPGauge °C Current GPU temperature of the device. DCGM_FI_DEV_POWER_USAGEGauge W Power usage of the device.
-
Autoscaling GPU Resources
-
To enable this feature, you MUST:
- Enable Autoscale for GPU Nodegroups that you want to scale on the VKS portal.
- Install Keda using Helm chart in your VKS cluster.
-
In the case you DO NOT install Keda in your cluster, VKS autoscaler feature will detect the
Pendingpods and scale the GPU Nodegroup automatically. This happens when the number of replicas of theDeploymentis greater than the number of available GPUs that you configured in theConfigMap. -
If you already installed Keda in your cluster, you can use the
ScaledObjectto scale the GPU Nodegroup based on the metrics that you want. For example, you can scale the GPU Nodegroup based on the GPU usage, memory usage, or any other metrics that you want. For example:apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: scaled-object spec: scaleTargetRef: name: scaling-app # The name of the Deployment, MUST in same namespace minReplicaCount: 1 # Optional. Default: 0 maxReplicaCount: 3 # Optional. Default: 100 triggers: # Will be trigger if either of these triggers is true - type: prometheus metadata: # prometheus-stack-kube-prom-prometheus serverAddress: http://prometheus-stack-kube-prom-prometheus.prometheus.svc.cluster.local:9090 metricName: engine_active query: sum(DCGM_FI_DEV_GPU_UTIL) / count(DCGM_FI_DEV_GPU_UTIL) / 100 threshold: '0.5' # Scale the GPU Nodegroup when the GPU usage is greater than 50% - type: prometheus metadata: # prometheus-stack-kube-prom-prometheus serverAddress: http://prometheus-stack-kube-prom-prometheus.prometheus.svc.cluster.local:9090 metricName: engine_active query: sum(DCGM_FI_DEV_MEM_COPY_UTIL) / count(DCGM_FI_DEV_MEM_COPY_UTIL) / 100 threshold: '0.5' # Scale the GPU Nodegroup when the GPU memory usage is greater than 50% -
The above manifest scales the GPU Nodegroup based on the GPU usage and memory usage. The
queryfield specifies the query to fetch the metrics from Prometheus. Thethresholdfield specifies the threshold value to scale the GPU Nodegroup. TheminReplicaCountandmaxReplicaCountfields specify the minimum and maximum number of replicas that the GPU Nodegroup can scale to. -
Now let's install Keda in your cluster by executing the below command:
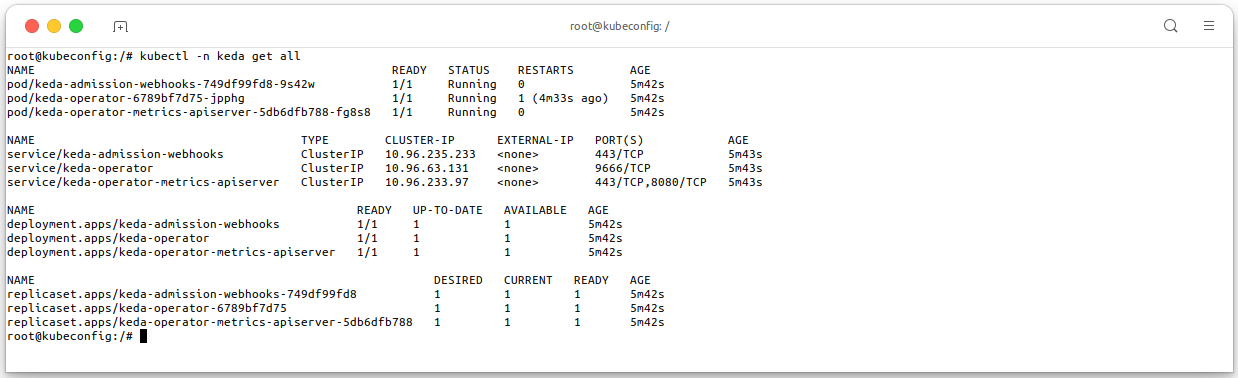
helm install --wait kedacore \ --namespace keda --create-namespace \ oci://vcr.vngcloud.vn/81-vks-public/vks-helm-charts/keda \ --version 2.14.2 kubectl -n keda get all
-
Apply scaling-app.yaml manifest to generate resources for testing the autoscaling feature. This manifest run 1 pod of CUDA VectorAdd Test and the GPU Nodegroup will be scaled to 3 when the GPU usage is greater than 50%.
kubectl apply -f \ https://github.com/vngcloud/kubernetes-sample-apps/raw/main/nvidia-gpu/manifest/scaling-app.yaml -
Apply scale-gpu.yaml manifest to create the
ScaleObjectfor the above application. This manifest will scale the GPU Nodegroup based on the GPU usage.kubectl apply -f \ https://github.com/vngcloud/kubernetes-sample-apps/raw/main/nvidia-gpu/manifest/scale-gpu.yaml kubectl get deploy # Check the ScaledObject kubectl get scaledobject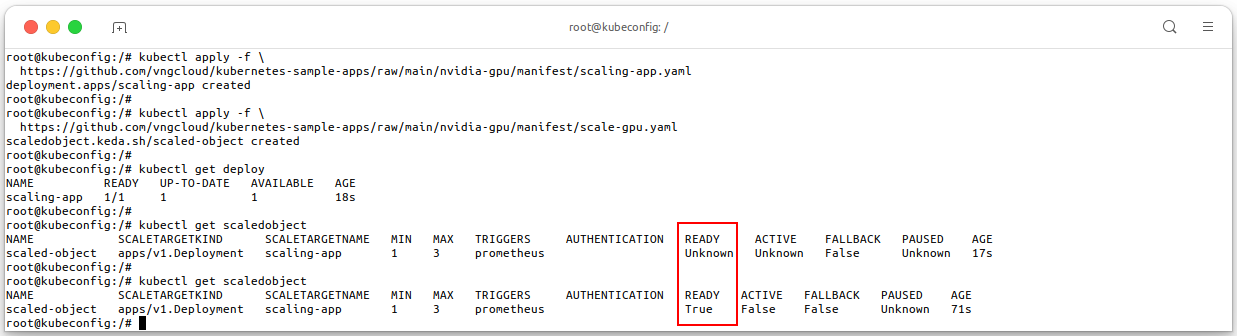
- When the
ScaledObjectReady value isTrue, the GPU Nodegroup will be scaled based on the GPU usage.
- When the